StackOverflow.com has had a huge impact on software development. Although I agree with Fred Brooks that there is no silver bullet in software development, StackOverflow.com has certainly played a significant role in developers learning quicker from others' experiences, being able to learn from many more peoples' experiences, and being more productive. StackOverflow.com allows developers to benefit from the advantages of social media with community sharing and community voting and improving of the answers provided there. Now, the StackOverflow Documentation Tour, which offers a tour of the new (beta) StackOverflow Documentation, advertises, "Together, we can do for Documentation what we did for Q&A." That's a lofty goal given what StackOverflow and the development community have done for questions and answers.
I have always enjoyed learning from software development "cookbooks" or "recipe-based" books. These example-heavy books have helped me to learn programming languages, frameworks, and libraries more quickly and to apply them in meaningful ways more quickly. Like many developers, I often find the answers to more detailed questions or issues I encounter on StackOverflow.com. This is largely explained by the fact that StackOverflow has so many "contributers" from the worldwide software development community. That vast number of developers increase the probability of any particular issue or need having been encountered before by someone else. StackOverflow Documentation combines the best of the example-heavy cookbooks and StackOverflow's community contributions by combining example-heavy documentation like that commonly presented in cookbooks with the expertise of an entire community that StackOverflow currently enjoys.
My first impression upon reading about StackOverflow Documentation was that it would undoubtedly be a huge success because it does combine the best of the "cookbooks" with the best of StackOverflow. However, as I've thought about it a bit more, I've started to think of some potential hurdles that might prevent it from achieving the success rate of the questions and answers StackOverflow. I describe these thoughts briefly in this post.
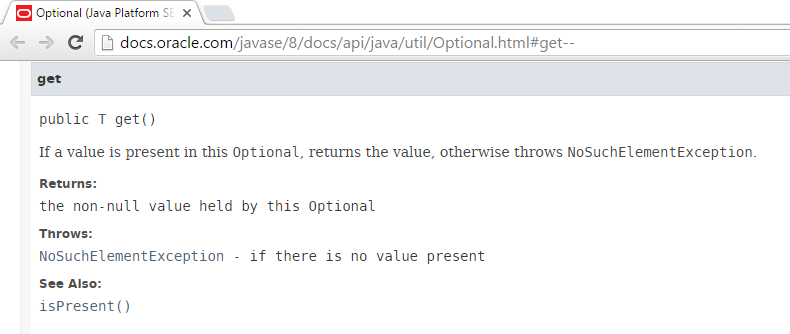
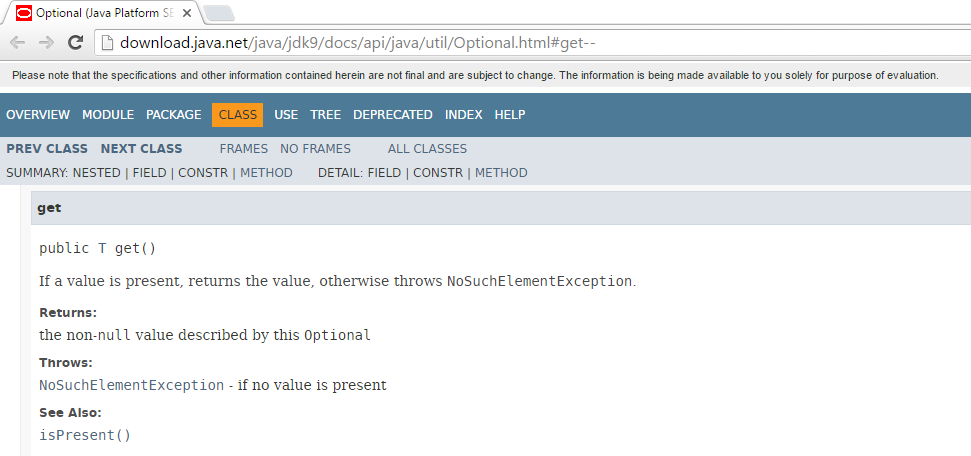
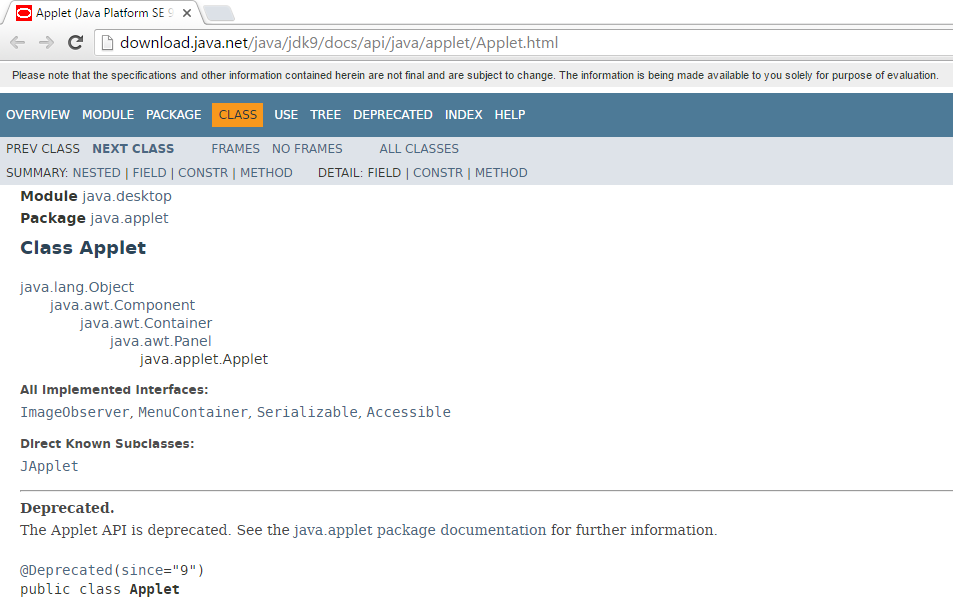
Although the documentation for some languages, frameworks, libraries, and toolkits is not very good, some is actually pretty well written. For example, I have long thought highly of the Spring Framework documentation. It's well-written and mixes text and many examples. Another example of well-written documentation with plenty of examples is the Java Tutorials. My most common use of StackOverflow related to Spring and Java has been to get answers to specific issues I've run into or "corner cases" that aren't in the documentation or that I don't know how to look up in the documentation. Basic examples of how to do general things in Spring and in Java have rarely been what I have needed StackOverflow for. Many official documentation sites now allow comments and feedback from the community as well.
I rarely go directly to StackOverflow to ask a specific question. Rather, I typically use a search engine such as Google to type in my search and allow the search engine to point me to potential references. StackOverflow matches are often high on the returned list and I definitely favor returned results that reference StackOverflow over lesser known sites. One of the most disheartening experiences in searching the web to resolve a particularly difficult issue is to have a search engine return no matches or very few matches with no StackOverflow matches. Much of StackOverflow Documentation's success may hinge on its code examples doing well in the search engine algorithms and on developers learning to give it the same preference many of us give to StackOverflow today when choosing which search engine results to look at first.
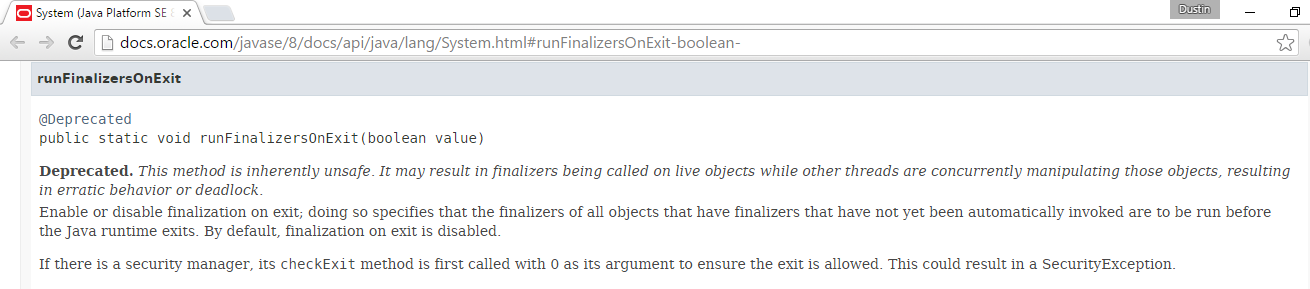
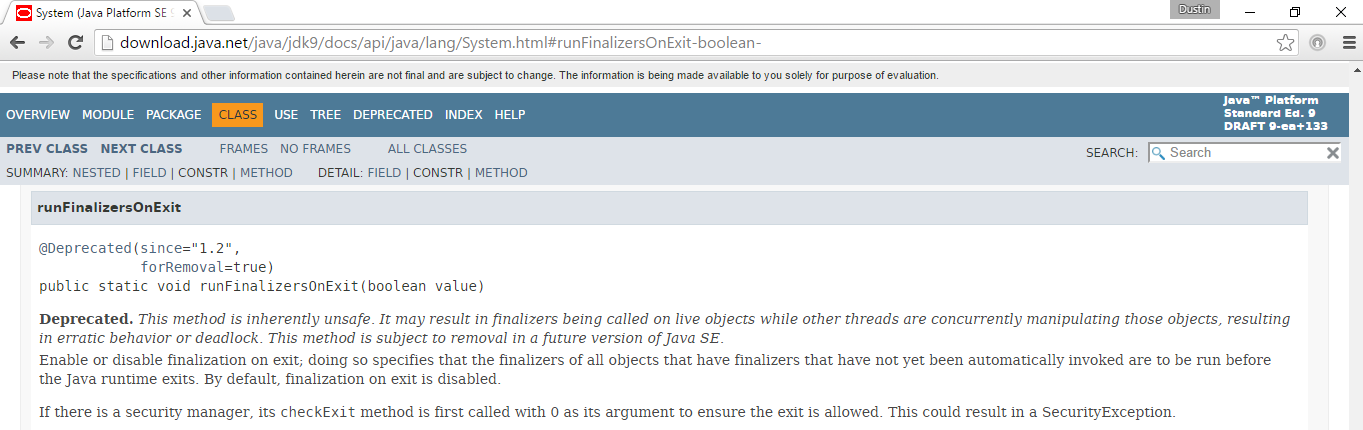
Besides the advantages of social collaboration that StackOverflow Documentation enjoys, I think a significant advantage of StackOverflow Documentation for developers will be that providing of version information with the examples. The web and blogosphere are full of code-heavy examples, but many of these examples don't providing date or version information. Even when dates are provided, it's not always clear to which versions of a language, framework, toolkit, or library the examples provide. StackOverflow Documentation specifically supports providing of version information and I think that will be extremely beneficial to users of the site. If a contributor associates the wrong version with the example, other community members will be quick to fix it. Even when an original contributor does not keep an example updated as versions change, the community often will likely do so.
Another interesting characteristic of StackOverflow Documentation is the vendor affiliations. StackOverflow Documentation partners include Microsoft, Xamarin (now part of Microsoft), DropBox, PubNub, and PayPal. I can envision these partnerships contributing to or taking away from the success of StackOverflow Documentation. If the partners do a good job of integrating their own documentation with the StackOverflow Documentation rather than just creating a case of developers needing to look in more places for "official" documentation, then it could lead to success. It will be interesting to see how the community edits to partner-affiliated topics will be moderated, censored, and responded to by individuals associated with the partner organization.
Another characteristic of StackOverflow Documentation that gives it a clear advantage over any alternative is its affiliation with the well-established question and answer portion. Developers who needed to create a new account and have an entirely different "rewards" system might be less likely to involve themselves. By sharing the total reputation between traditional Q&A StackOverflow and StackOverflow Documentation, a developer might be more likely to move between the two. This also allows a developer to reference his or her own entries in one of the forums from the other forum when appropriate. StackOverflow Documentation also offers its own specific badges which might be the incentive experienced StackOverflow users need to be active in StackOverflow Documentation.
I expect that StackOverflow Documentation will be a helpful resource and likely a successful one. However, achieving the same level of prominence as its question and answer counterpart may be difficult as the need for community-managed documentation may not be as great as the need for community-managed question and answers was when StackOverflow.com entered the scene. On the other hand, there were questions and answer forums before StackOverflow (such as JavaRanch), but their existence did not prevent StackOverflow.com from becoming to go-to resource for many developers.